












 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


图像分类是什么?AlexNet手写数字图像识别
更新时间:2022年12月07日16时57分 来源:传智教育 浏览次数:
图像分类
图像分类实质上就是从给定的类别集合中为图像分配对应标签的任务。也就是说我们的任务是分析一个输入图像并返回一个该图像类别的标签。
假定类别集为categories = {dog, cat, panda},之后我们提供一张图片给分类模型,如下图所示:

分类模型给图像分配多个标签,每个标签的概率值不同,如dog:95%,cat:4%,panda:1%,根据概率值的大小将该图片分类为dog,那就完成了图像分类的任务。下面利用AlexNet完成图像分类过程的讲解。
AlexNet完手写数字势识别
2012年,AlexNet横空出世,该模型的名字源于论文第一作者的姓名Alex Krizhevsky 。AlexNet使用了8层卷积神经网络,以很大的优势赢得了ImageNet 2012图像识别挑战赛。它首次证明了学习到的特征可以超越手工设计的特征,从而一举打破计算机视觉研究的方向。
AlexNet使用ImageNet数据集进行训练,但因为ImageNet数据集较大训练时间较长,我们仍用前面的MNIST数据集来演示AlexNet。读取数据的时将图像高和宽扩大到AlexNet使用的图像高和宽227。这个通过tf.image.resize_with_pad来实现。
数据读取
首先获取数据,并进行维度调整:
import numpy as np # 获取手写数字数据集 (train_images, train_labels), (test_images, test_labels) = mnist.load_data() # 训练集数据维度的调整:N H W C train_images = np.reshape(train_images,(train_images.shape[0],train_images.shape[1],train_images.shape[2],1)) # 测试集数据维度的调整:N H W C test_images = np.reshape(test_images,(test_images.shape[0],test_images.shape[1],test_images.shape[2],1))由于使用全部数据训练时间较长,我们定义两个方法获取部分数据,并将图像调整为227*227大小,进行模型训练:
# 定义两个方法随机抽取部分样本演示# 获取训练集数据def get_train(size):
# 随机生成要抽样的样本的索引
index = np.random.randint(0, np.shape(train_images)[0], size)
# 将这些数据resize成227*227大小
resized_images = tf.image.resize_with_pad(train_images[index],227,227,)
# 返回抽取的
return resized_images.numpy(), train_labels[index]# 获取测试集数据 def get_test(size):
# 随机生成要抽样的样本的索引
index = np.random.randint(0, np.shape(test_images)[0], size)
# 将这些数据resize成227*227大小
resized_images = tf.image.resize_with_pad(test_images[index],227,227,)
# 返回抽样的测试样本
return resized_images.numpy(), test_labels[index]
调用上述两个方法,获取参与模型训练和测试的数据集:
# 获取训练样本和测试样本 train_images,train_labels = get_train(256) test_images,test_labels = get_test(128)为了让大家更好的理解,我们将数据展示出来:
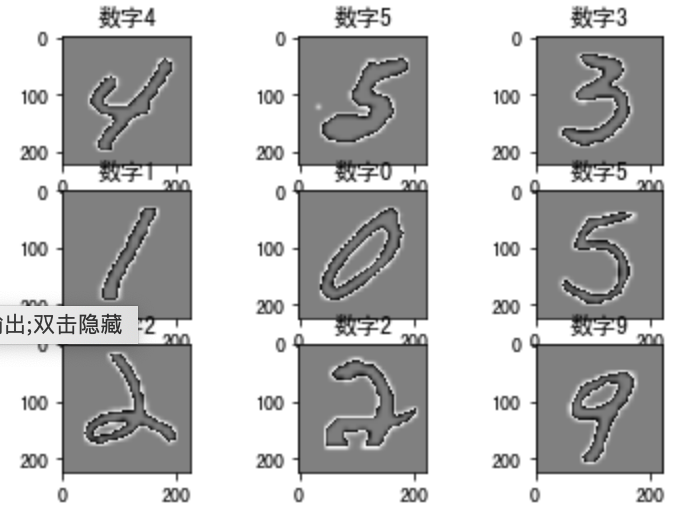
# 数据展示:将数据集的前九个数据集进行展示for i in range(9):
plt.subplot(3,3,i+1)
# 以灰度图显示,不进行插值
plt.imshow(train_images[i].astype(np.int8).squeeze(), cmap='gray', interpolation='none')
# 设置图片的标题:对应的类别
plt.title("数字{}".format(train_labels[i]))
结果为:
最新资讯
0
分享到:




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
